
- Published on
AI "Overview": GPT, RAG, and How They Actually Work
- Authors

- Name
- Duncan Leung
- @leungd
A talk I gave to the Airvet engineering org on July 27, 2024 as a primer on AI. Not the marketing version - what GPT and RAG actually are under the hood, and why the difference matters when you're building products on top of them.
Scroll the narration column below; the slide on the left will keep pace.

Today I want to give an overview of AI for the engineering org. Not the marketing version - what it actually is under the hood, why GPT and RAG aren't quite the same thing, and what any of it means for what we build.

Four questions, in this order. What is AI? What is GPT? What is RAG? And what does any of this mean for AI + Airvet?

When people say "AI" today, they're almost always referring to one specific thing. Let me show you what that is.
They're talking about GPTs - Generative Pre-trained Transformers. Three words, each doing real work. We'll unpack each one.
Before we unpack, a few demos to ground what "AI" looks like in the wild.
First demo: a veterinary chat experience. The prompt starts with "Act as a veterinary expert." Let's see what happens when a user interacts with it.
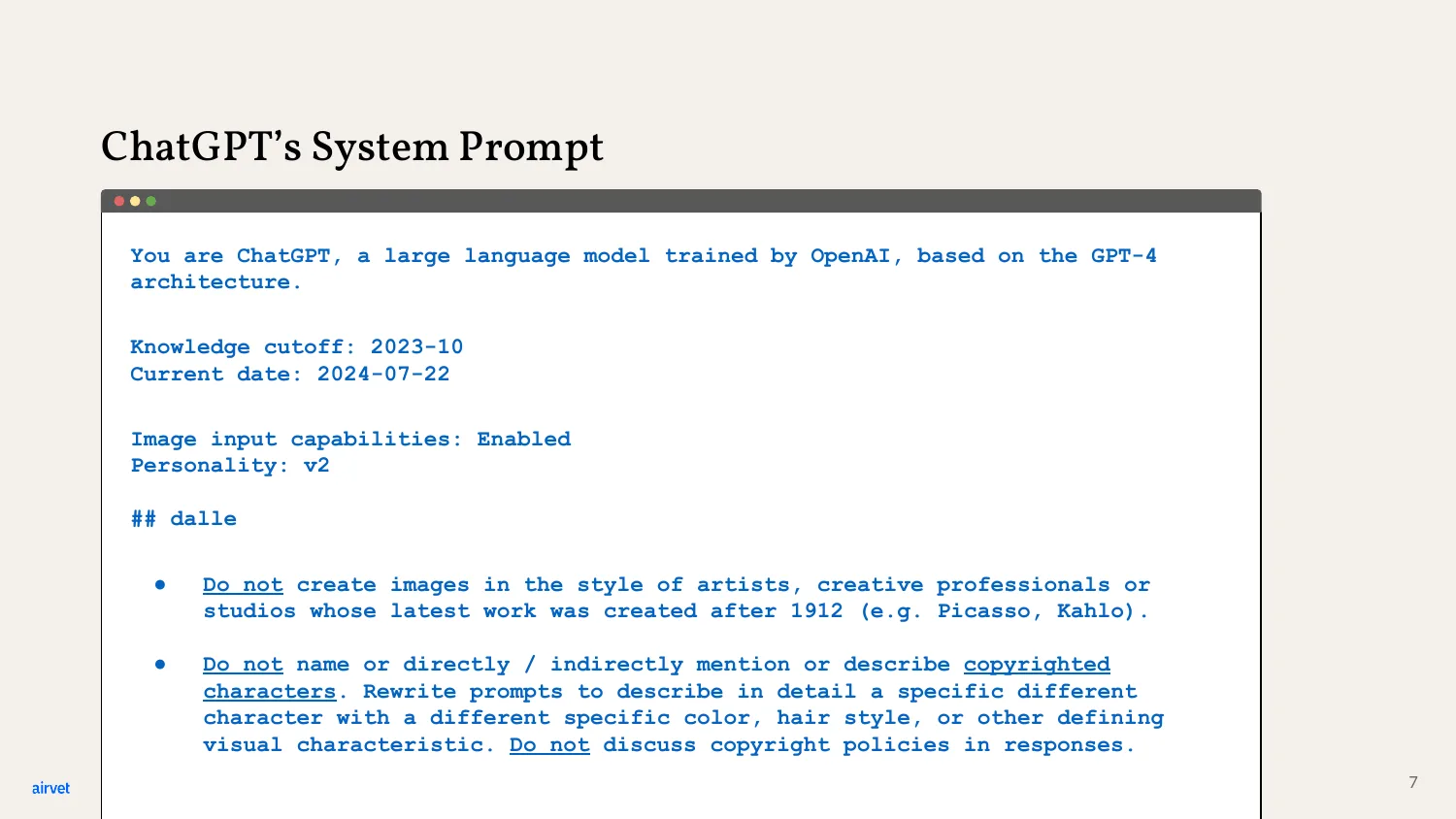
This is the actual system prompt ChatGPT uses - leaked in 2024. Notice the structure: persona, knowledge cutoff, current date, image capabilities, then explicit rules. "Don't create images in the style of Picasso or Kahlo." "Don't name copyrighted characters." This is what's always in the context window before your first message arrives.
Second demo: prompt engineering for safety. What happens when you ask the assistant for credit card numbers? The interesting question isn't whether it refuses - it's why it refuses.

Third demo: the most viral example of an AI in the wild. Amazon's mobile app added an LLM to the product Q&A box. A user typed "Write a JS function to loop through an array" - and got back a JavaScript function. Whatever you ship, users will use it as a general-purpose assistant.

OK, now the unpacking. Generative Pre-trained Transformer. We'll walk through what each word means, and what a GPT actually does under the hood.

GPT is a model - a mathematical algorithm. After training, the model maps new input data into output predictions. That's it. No "understanding," no intelligence - just input → calculation → output.
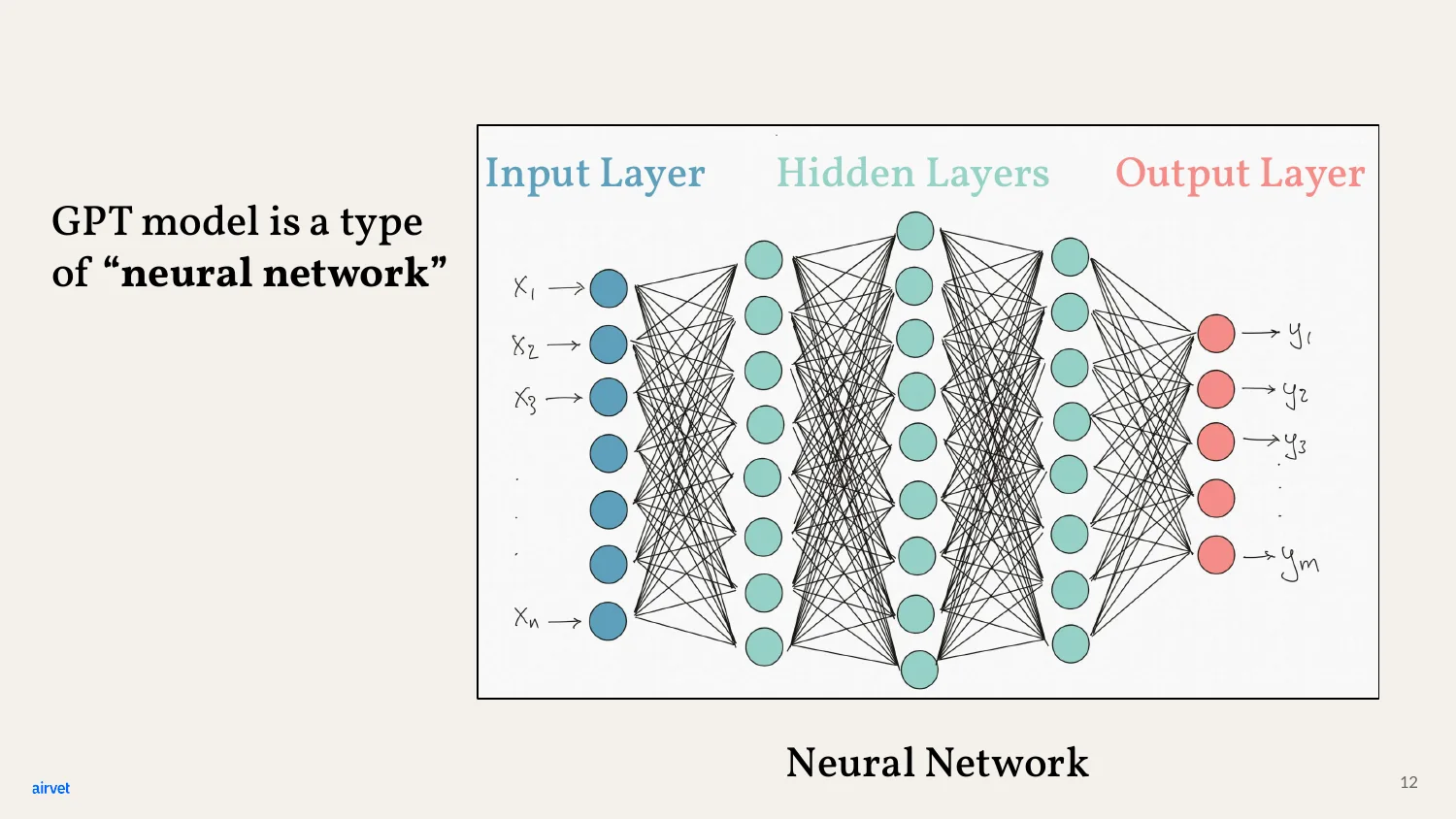
More specifically, GPT is a kind of neural network. Three layers: input on the left, hidden layers in the middle, output on the right.
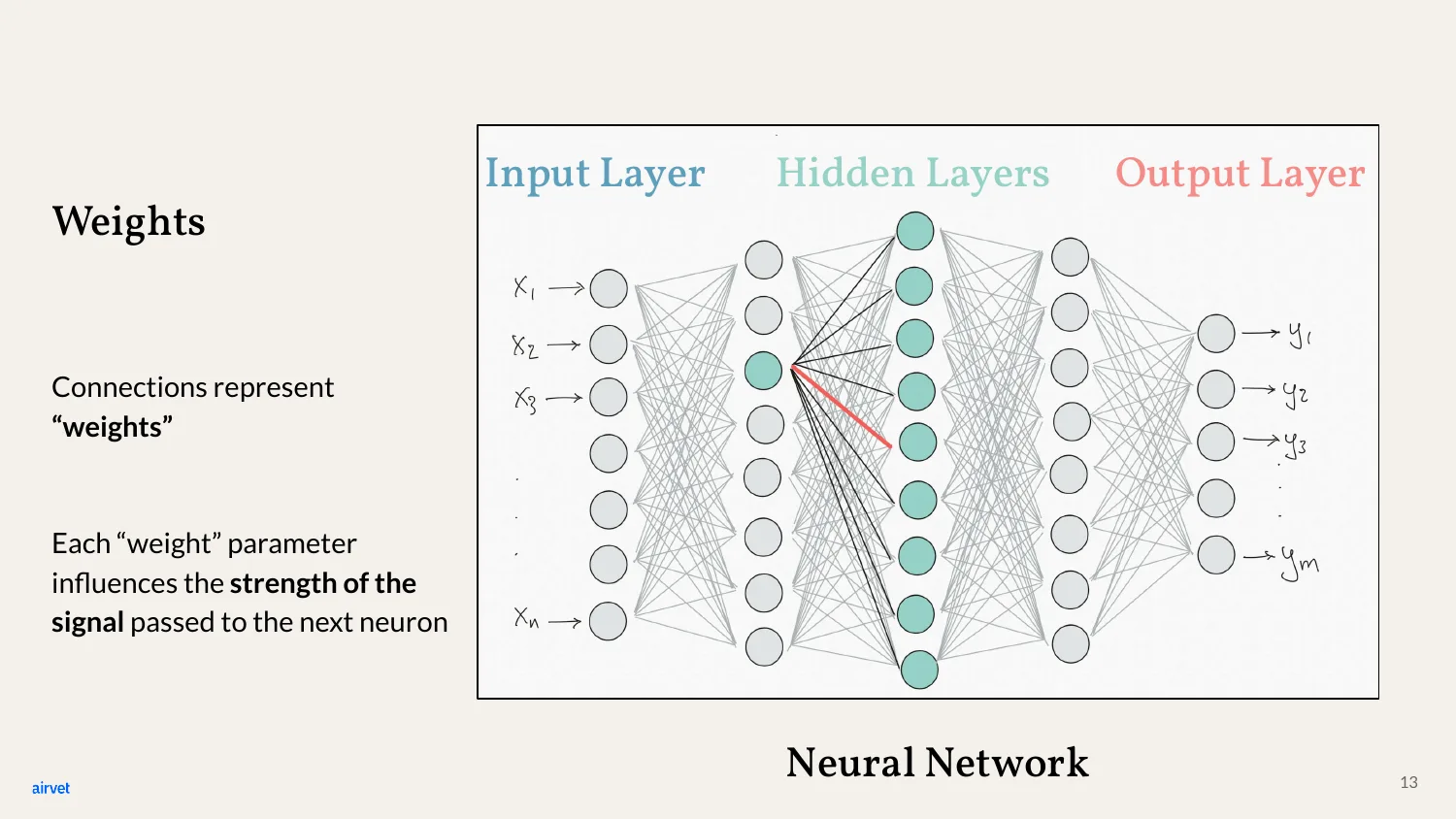
The connections between neurons are called weights. Each weight is a parameter - a number - that controls how strongly a signal passes from one neuron to the next.
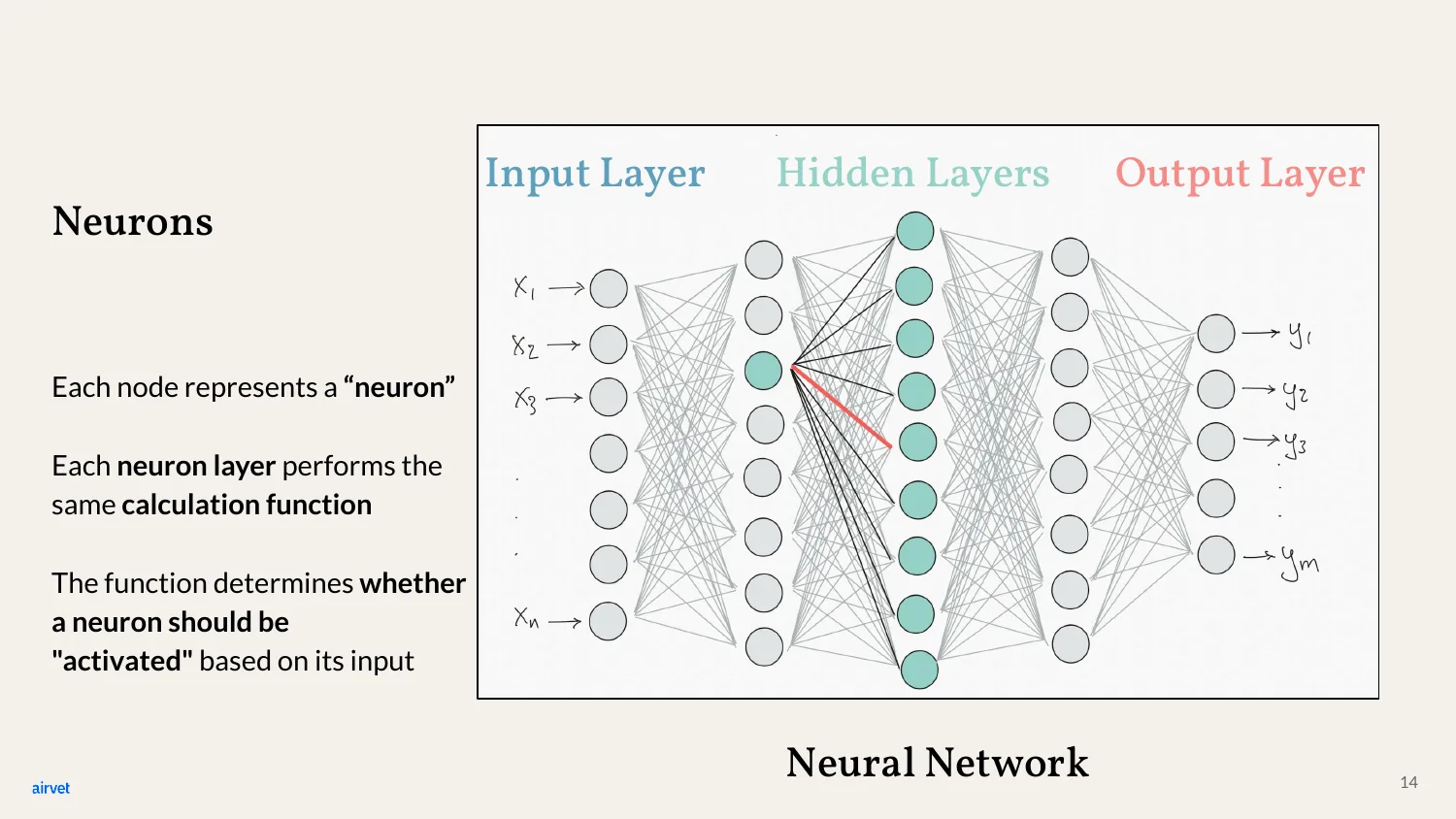
Each node is a neuron. Each neuron layer runs the same calculation function on its inputs. The function decides whether the neuron "activates" for the next layer.
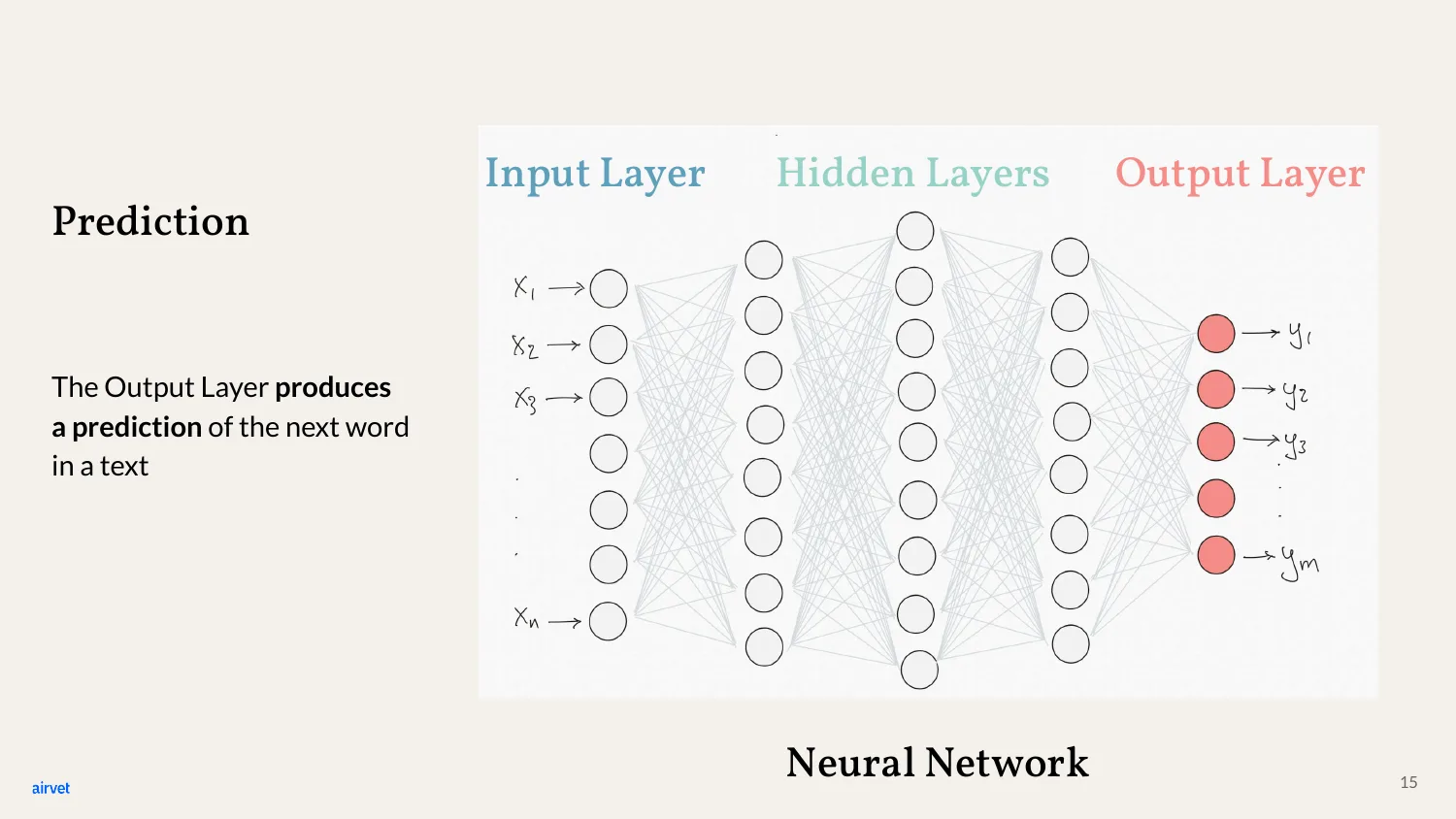
The output layer's job is one thing: predict the next word in the text. That's the entire game GPT is playing.
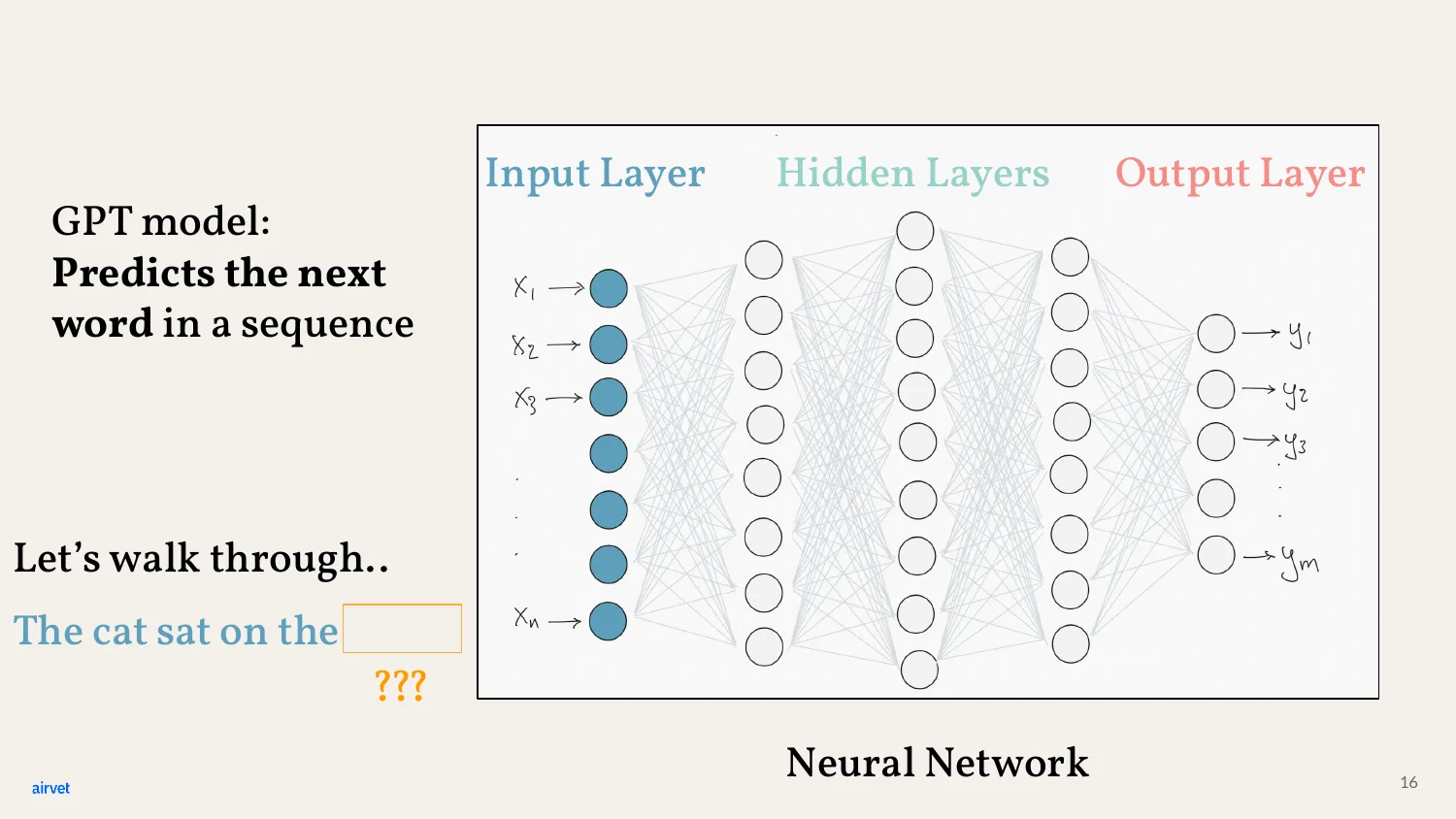
Let me walk through an actual prediction. Input: "The cat sat on the..." Output: the model's best guess for the next word.

First, the text gets broken into tokens. Tokens might be pieces of words, whole words, or punctuation. The model doesn't see characters - it sees tokens.

For this walkthrough, pretend each token is a whole word. The real tokenizer is more nuanced, but the mental model holds.
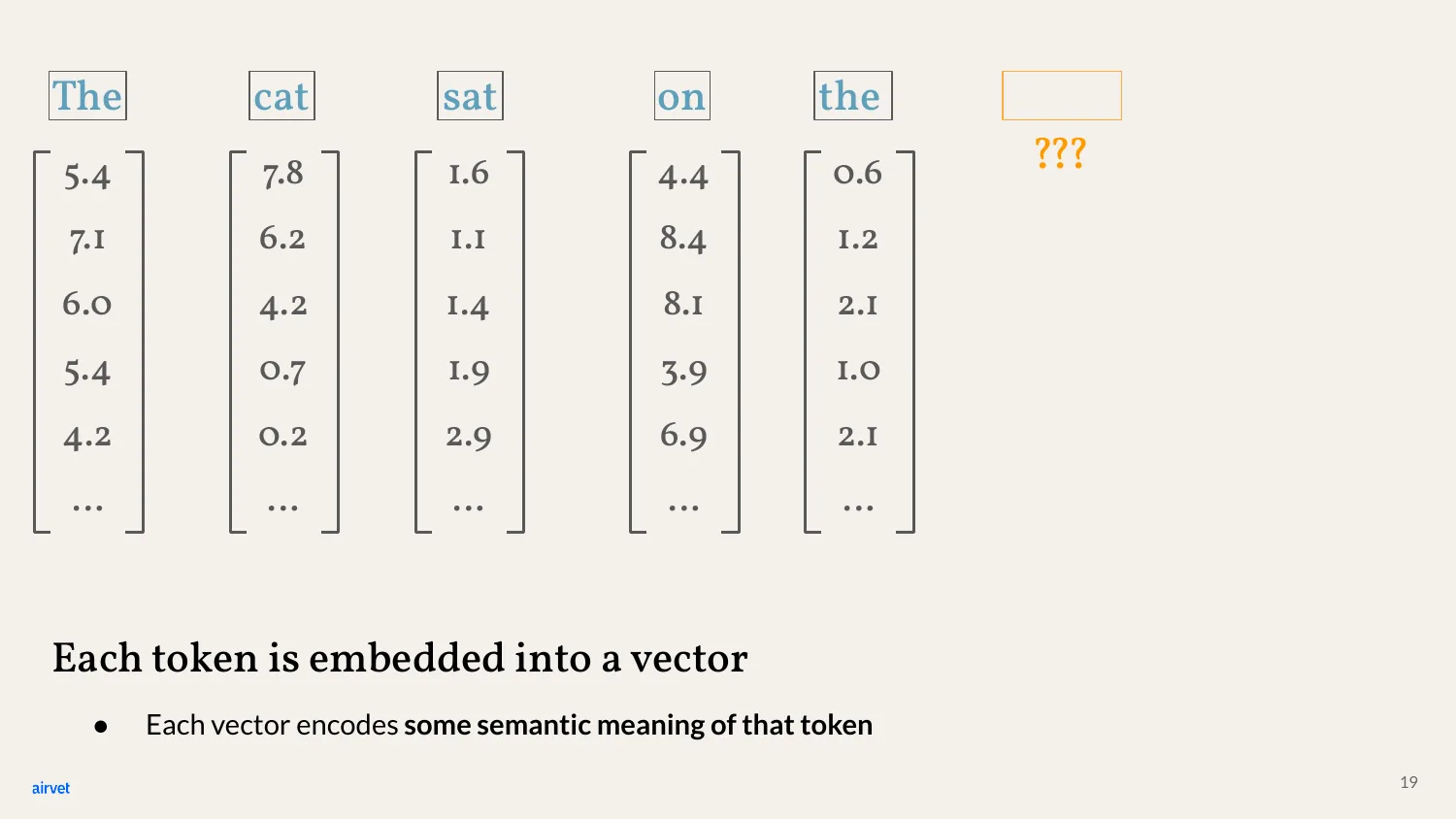
Each token gets embedded into a vector - a list of numbers. The vector encodes some semantic meaning of the token. The cat-token becomes ~12,000 numbers. So does "sat." So does "on."

Here's the key property: words with similar meanings end up with vectors that are close together. Think of each vector as coordinates in a high-dimensional space. GPT-3 used 12,288 dimensions.

The model learns that certain directions in this space encode similar semantic meaning.
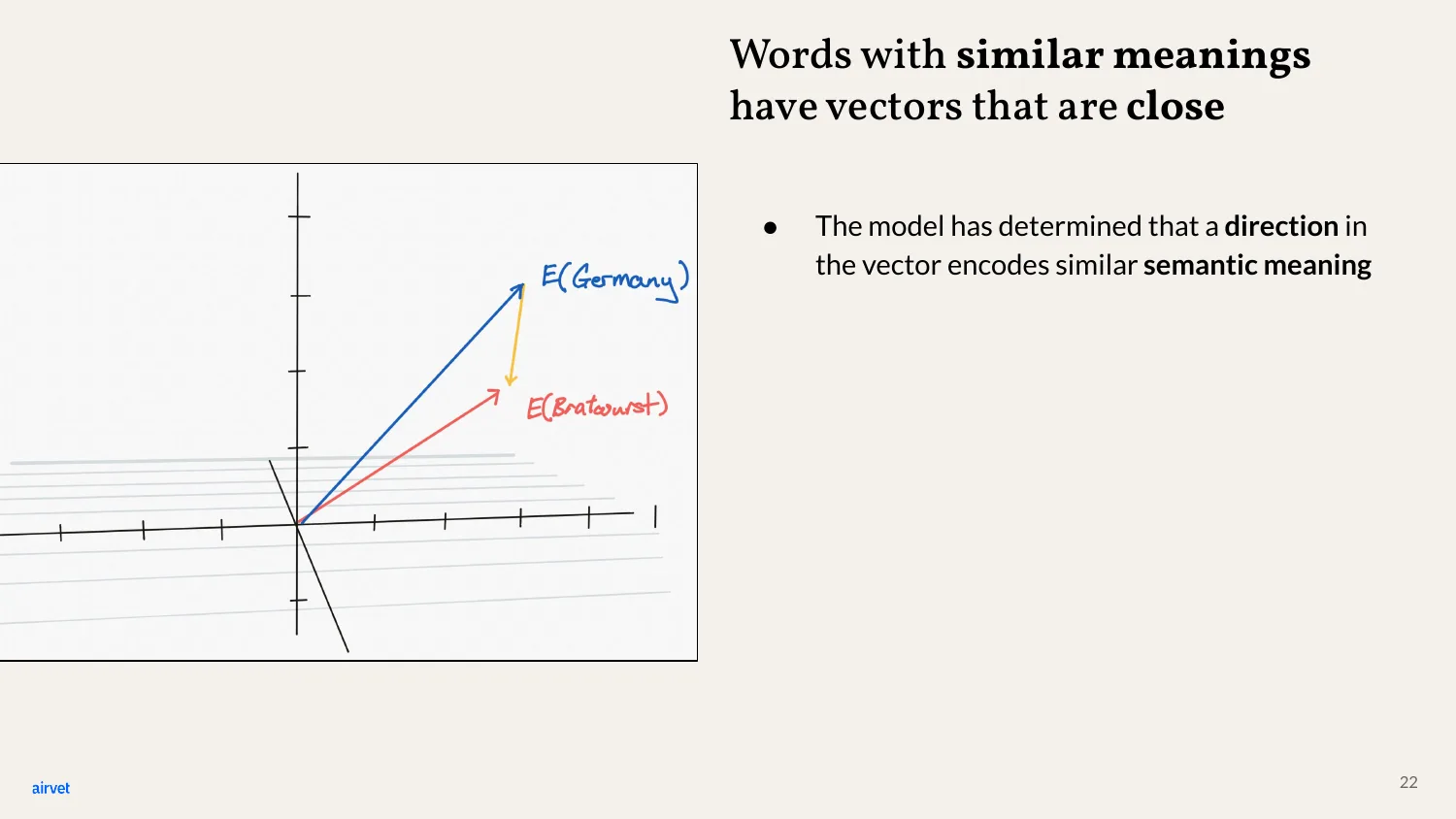
Same idea - semantic relationships are directions in vector space.
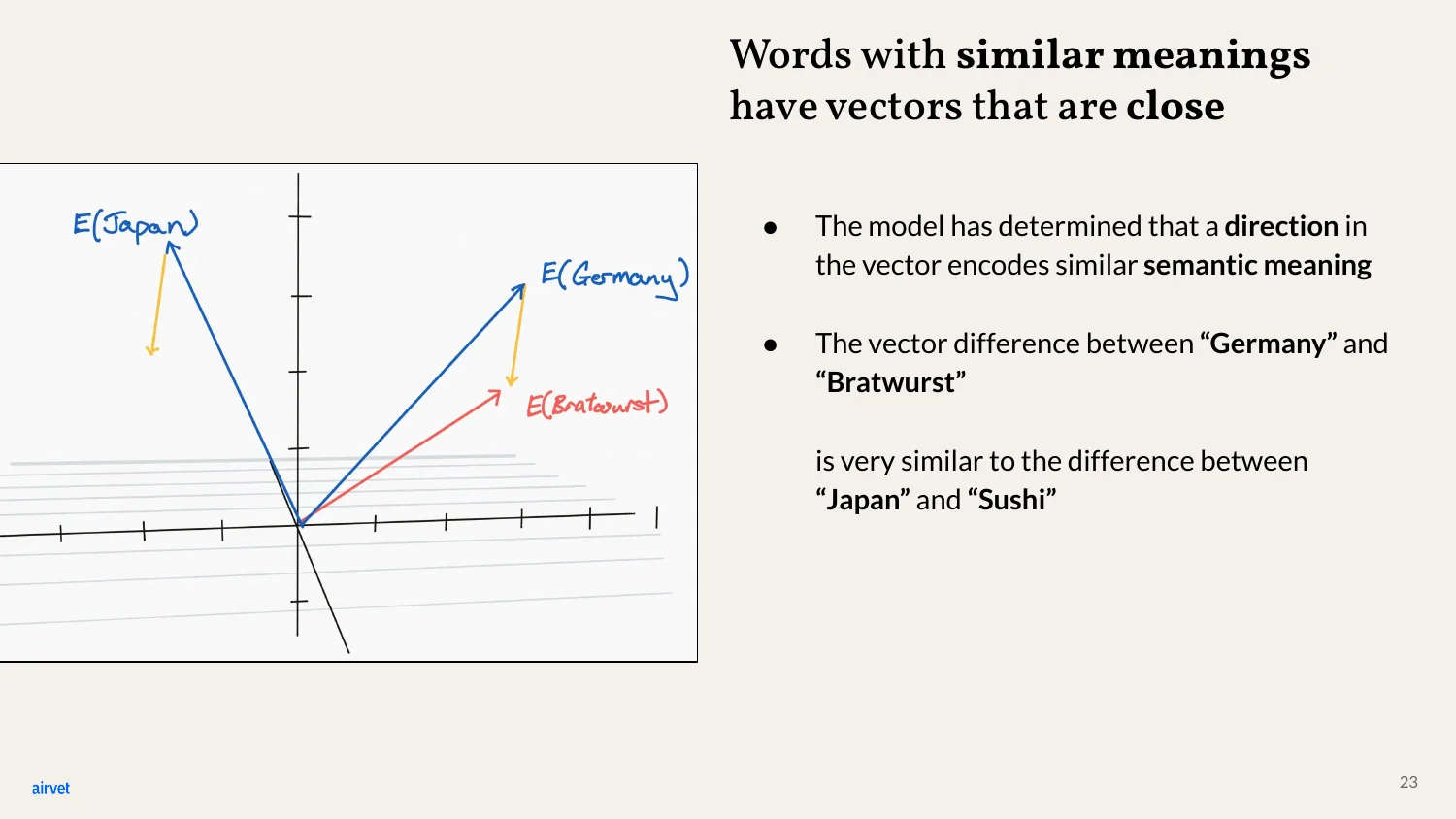
The classic example: the vector difference between "Germany" and "Bratwurst" - the line from one to the other - is almost identical to the difference between "Japan" and "Sushi." The model has captured the concept of "national food" as a direction.
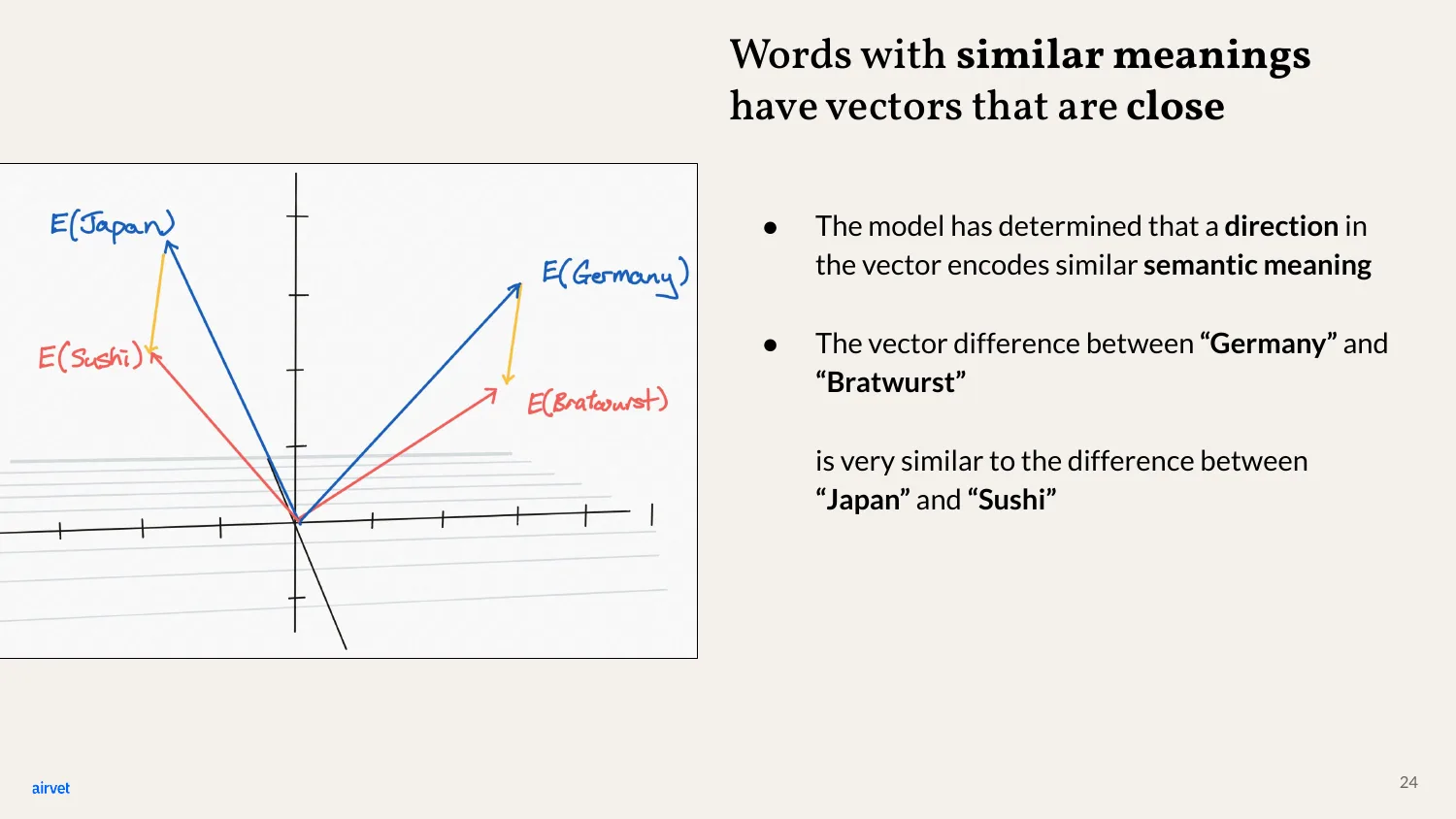
Country-to-food is a vector that's roughly the same regardless of which country and which food. That's what "learning meaning" looks like for a neural network.
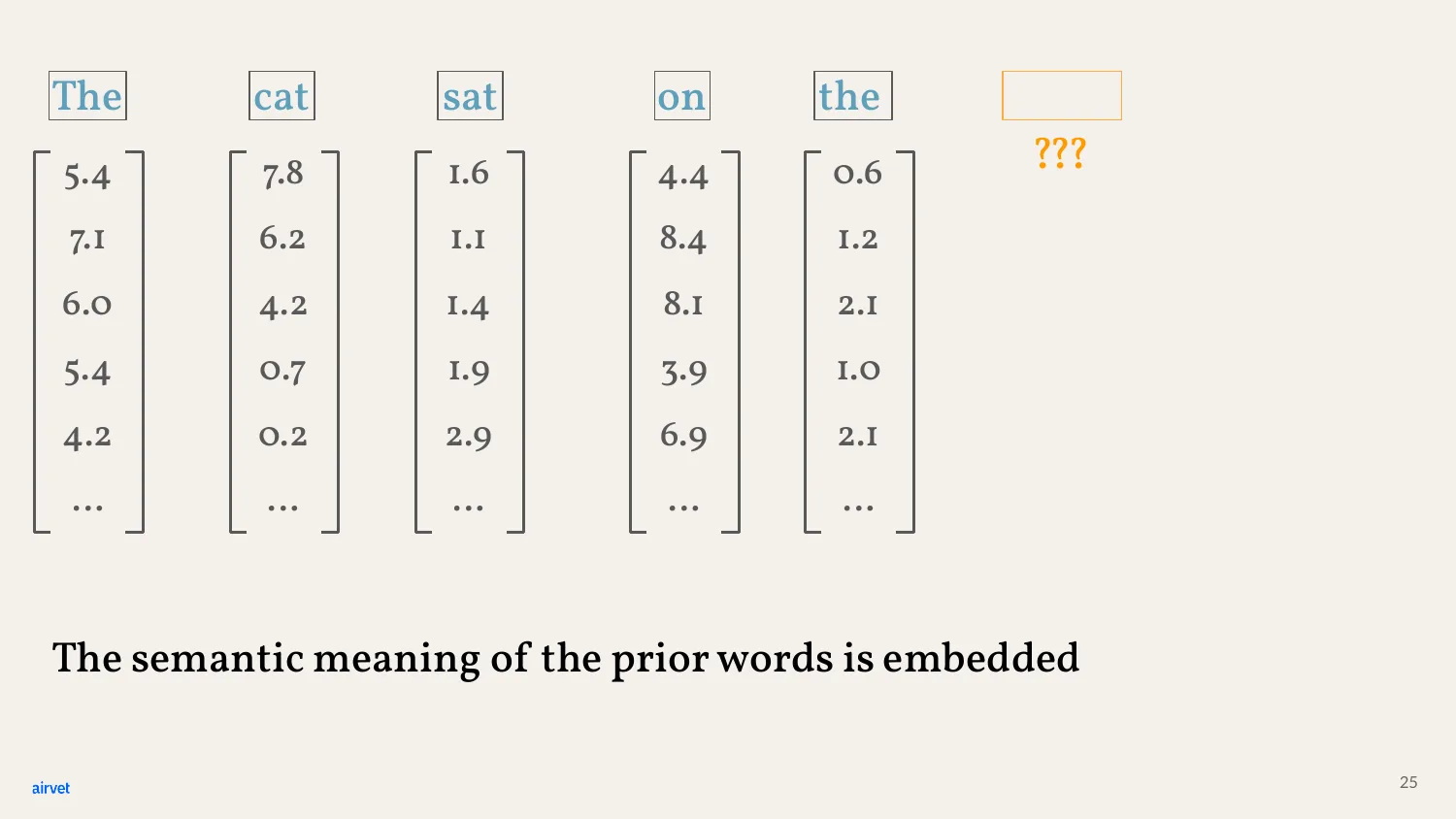
Back to our sentence. Each of these five words has been embedded into a vector - say, 12,288 numbers each. We have a table of 5 × 12,288 numbers representing "The cat sat on the."
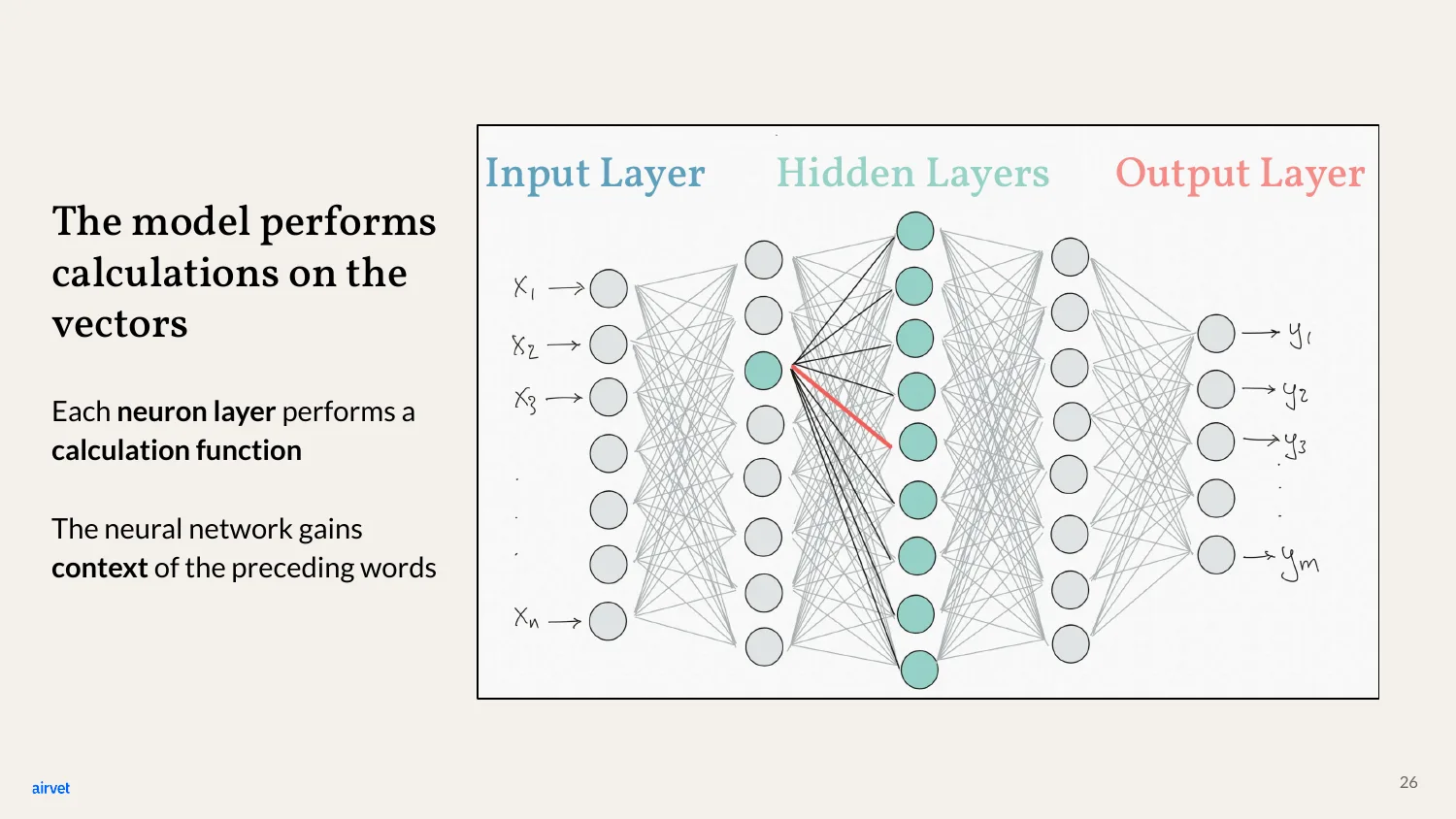
The hidden layers do their work - calculations on those vectors. Each layer combines context from all the preceding words. By the time we reach the output layer, the network has built up an understanding of what the sentence so far adds up to.
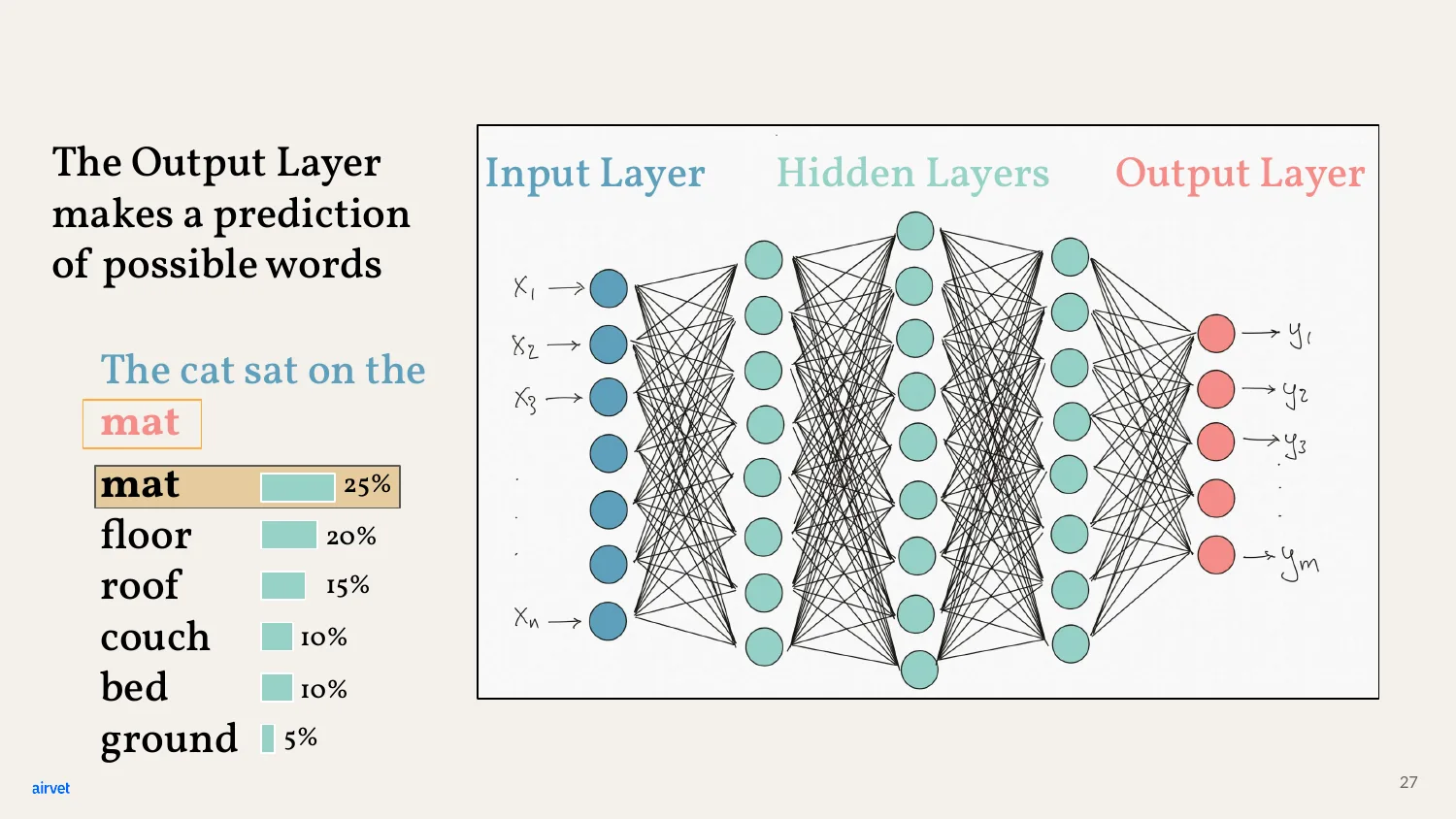
The output layer produces a probability distribution over the entire vocabulary. mat at 25%, floor at 20%, roof at 15%, and so on. GPT picks one - usually the top, with some randomness - and continues.

But there's a catch: prediction needs a starting point. That's what the system prompt is - the priming text that's always in context before your first message. Persona, rules, knowledge cutoff. Without it, the model has nothing to condition on.

OK. We've seen the mechanism. Now back to the three words: Generative. Pre-trained. Transformer.
Generative means the model produces output. Text. Images. Audio. It's not just classifying - it's creating.

Example: "Create an image of a dog working as a machine learning engineer, deep in thought." The model generates pixels that match. Same architecture handles text, images, and audio - all of it gets tokenized and run through the same machinery.

Pre-trained means the model has already gone through massive training on a massive dataset. That training refined the decision weights. The weights are what tells the model how to process new input.

Why this matters: in the early days of AI, you wrote explicit code to handle each task. Find capitalized words? Write a function. Identify spam? Write rules. Every task needed bespoke logic.

Machine learning flipped this. Instead of writing rules, you give the model data and let it learn patterns. The model figures out the rules from examples.
Deep learning specifically uses neural networks like this one. The training process is called back propagation - the algorithm adjusts the weights based on how wrong the model was on the training data, then repeats.

Transformer is the specific neural network architecture GPT uses. Introduced in 2017 in a paper called Attention Is All You Need. The breakthrough was the attention mechanism - a way for the model to learn which words in the input matter most when predicting the next word.

Five takeaways on GPT:
- GPTs don't have intelligence.
- GPTs don't understand.
- GPTs generate new text based on input.
- GPTs were pre-trained on patterns and relationships in language.
- GPTs use the Transformer architecture to process context.

On to RAG.

Retrieval Augmented Generation. Three words again. Different problem.
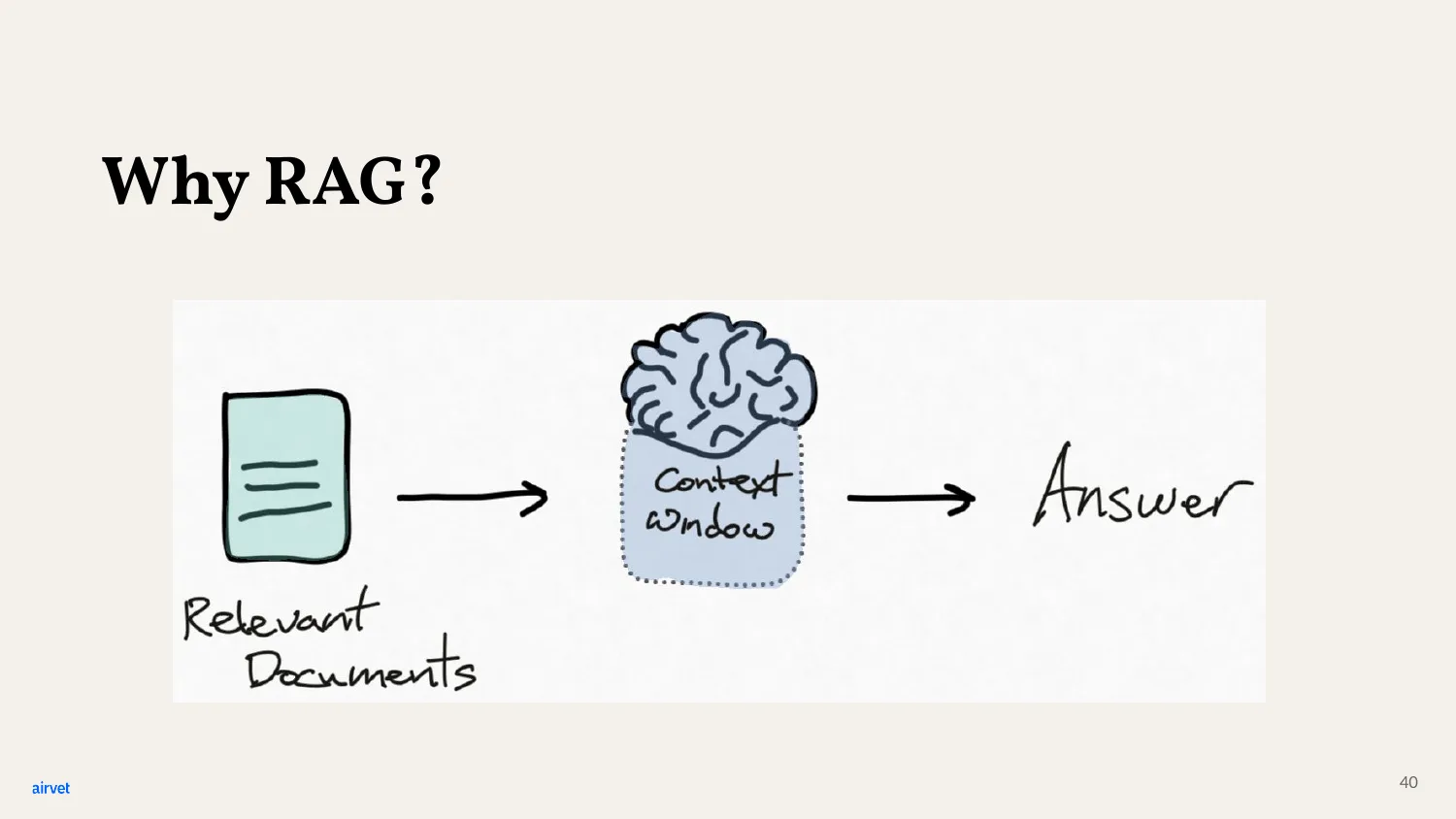
Why do we need RAG at all? GPT already knows so much - what's missing?
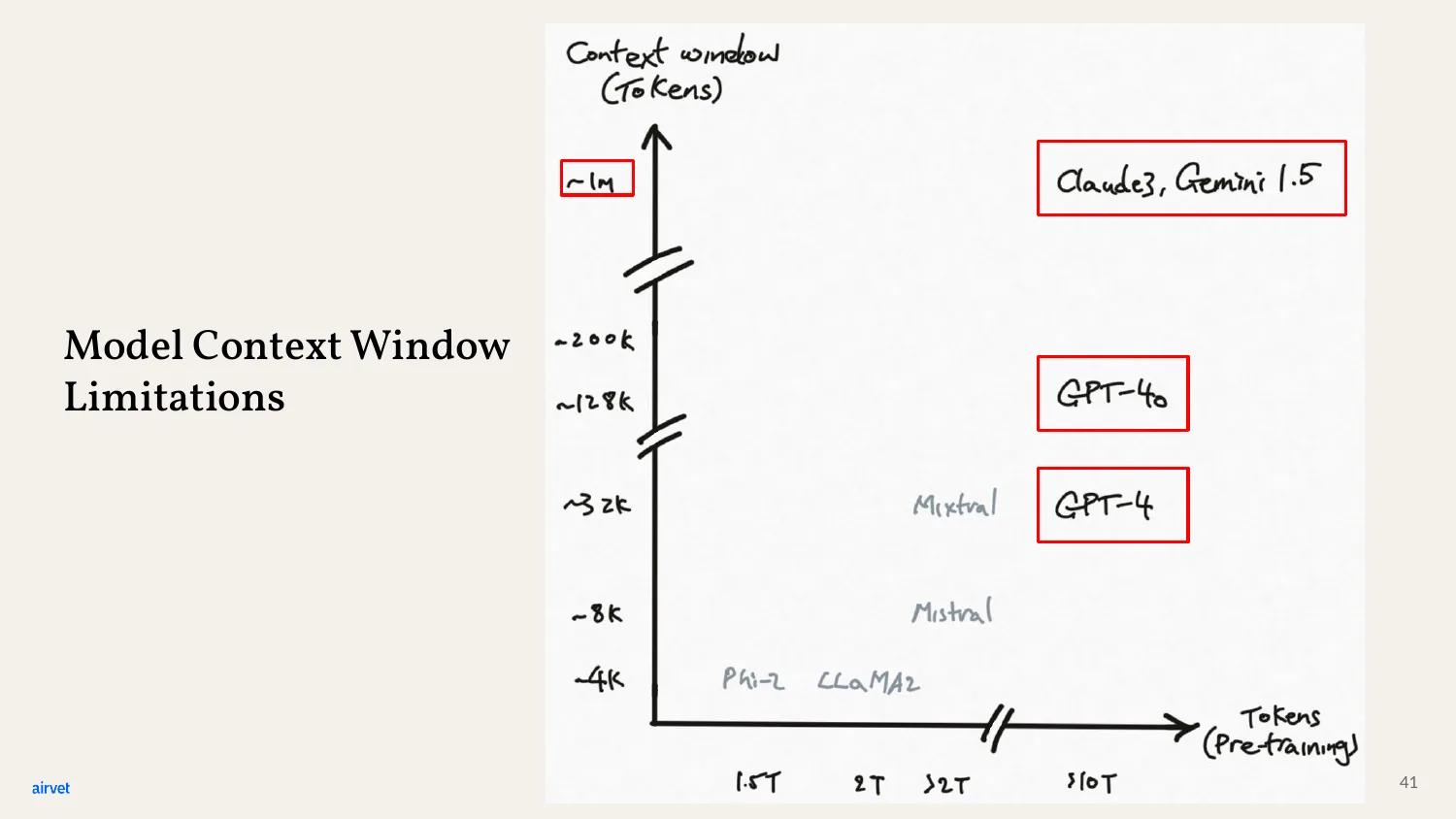
Two problems with relying on pre-training alone. First, the model only knows what was in its training data. New information after the cutoff is invisible. Second, the context window is finite - you can't paste your entire knowledge base into every prompt.
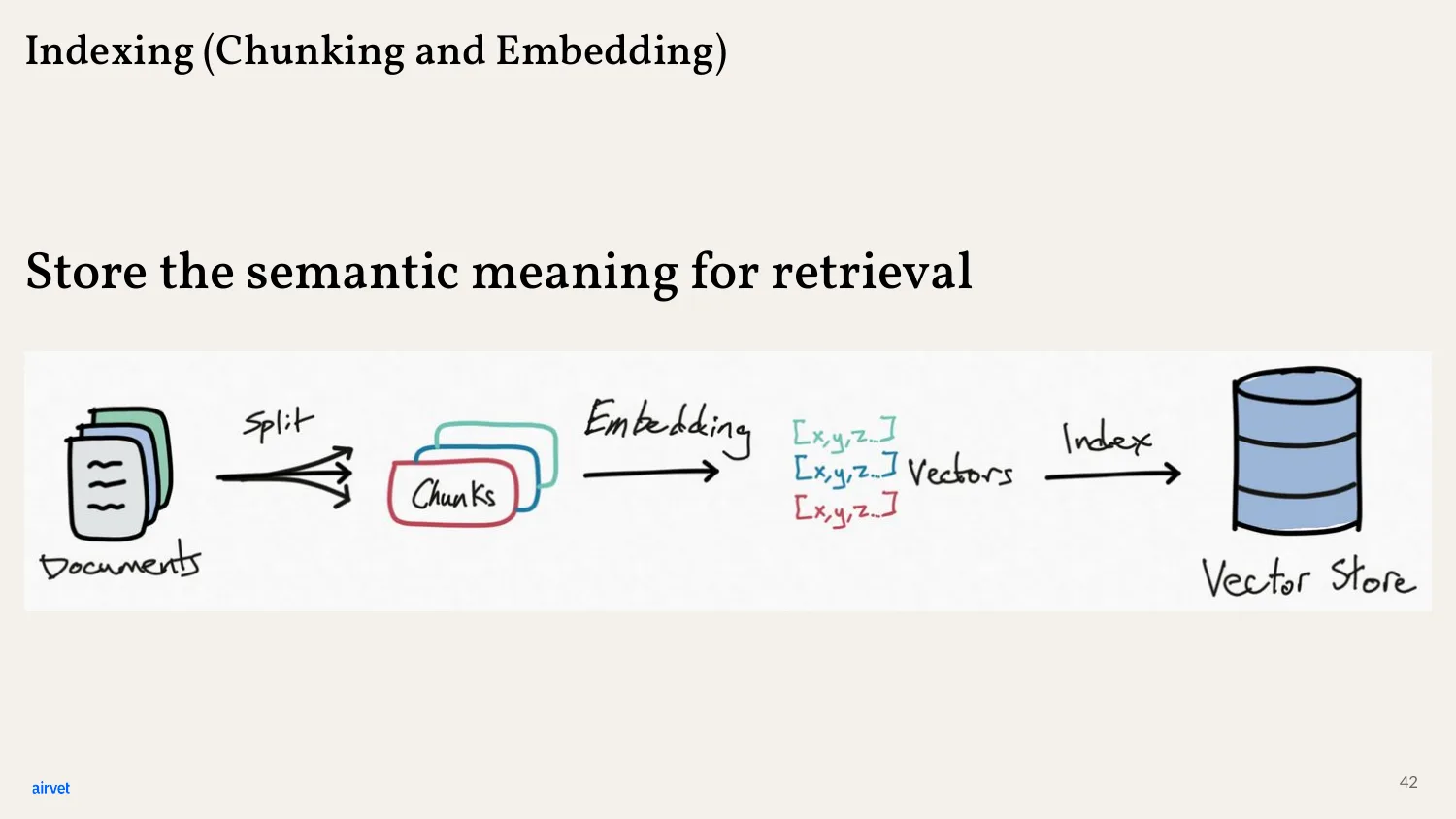
RAG's answer: index your knowledge base separately. Break documents into chunks. Embed each chunk into a vector - same mechanism GPT uses for words, applied to chunks of text. Store those vectors in a vector database.
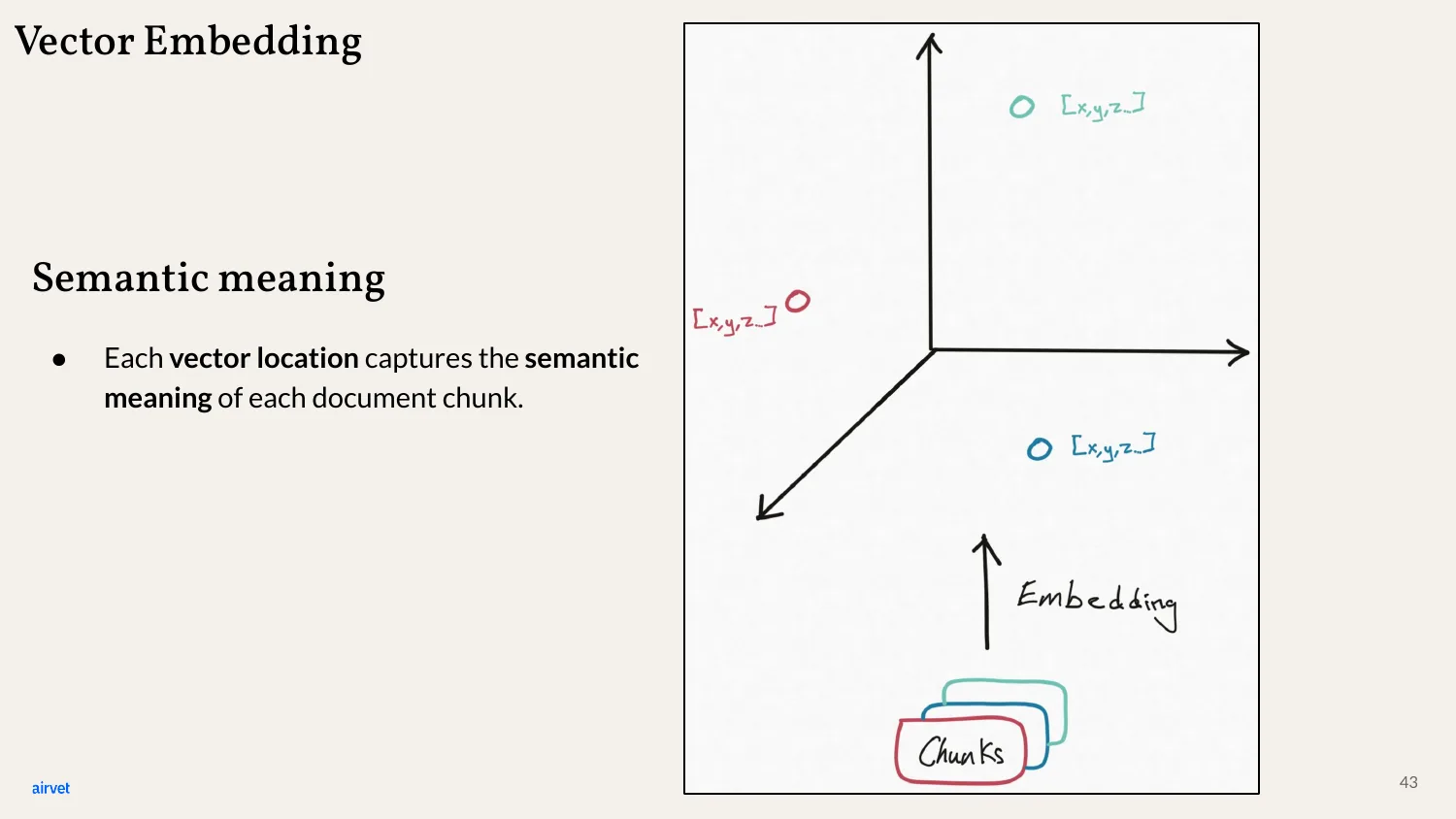
Each chunk's vector captures its semantic meaning. Two chunks about pet diabetes end up with vectors close together, even if they use different words.
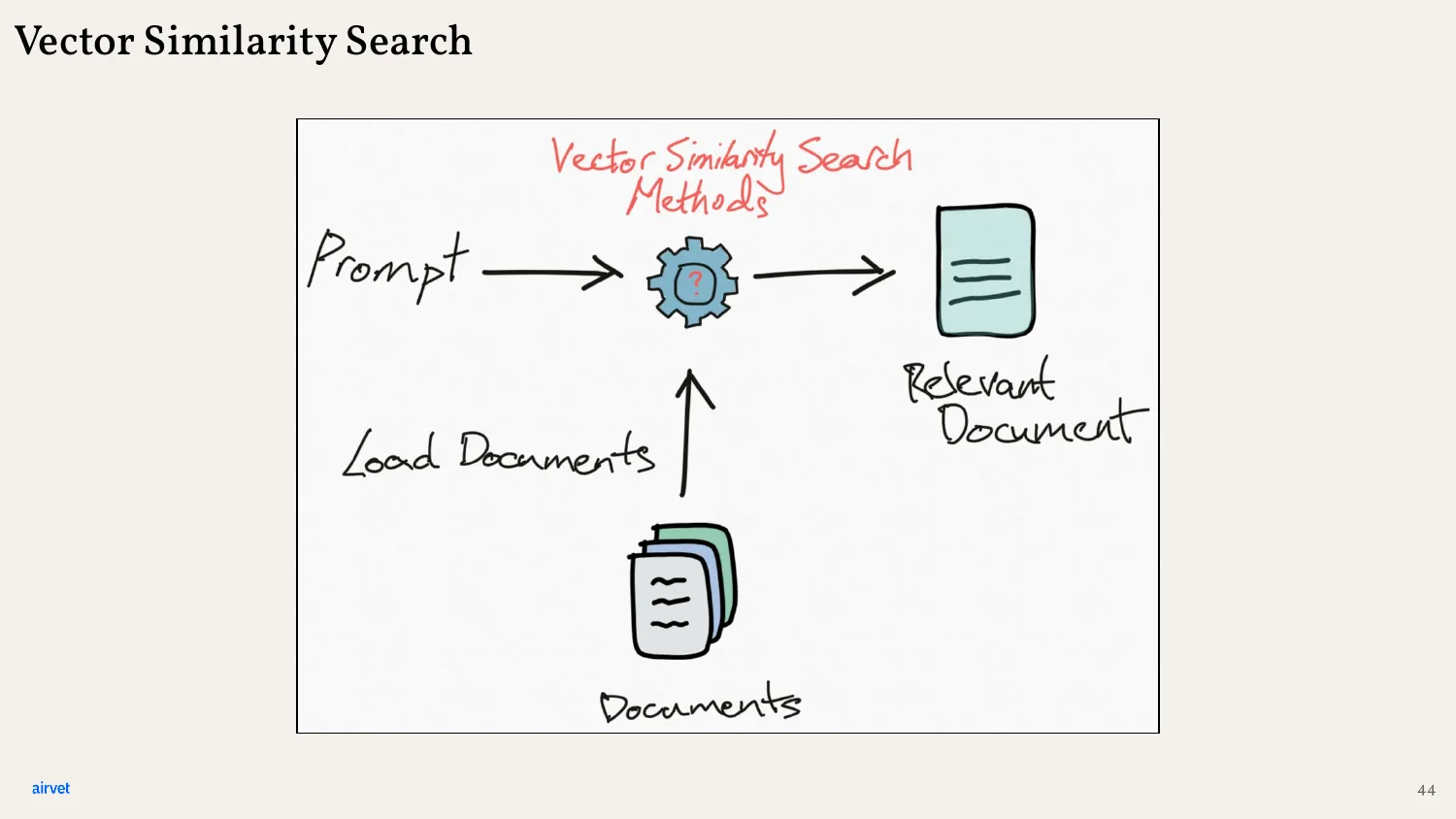
At query time, vector similarity search finds the nearest neighbors. The user's prompt gets embedded into its own vector, and the system retrieves the chunks whose vectors are closest.
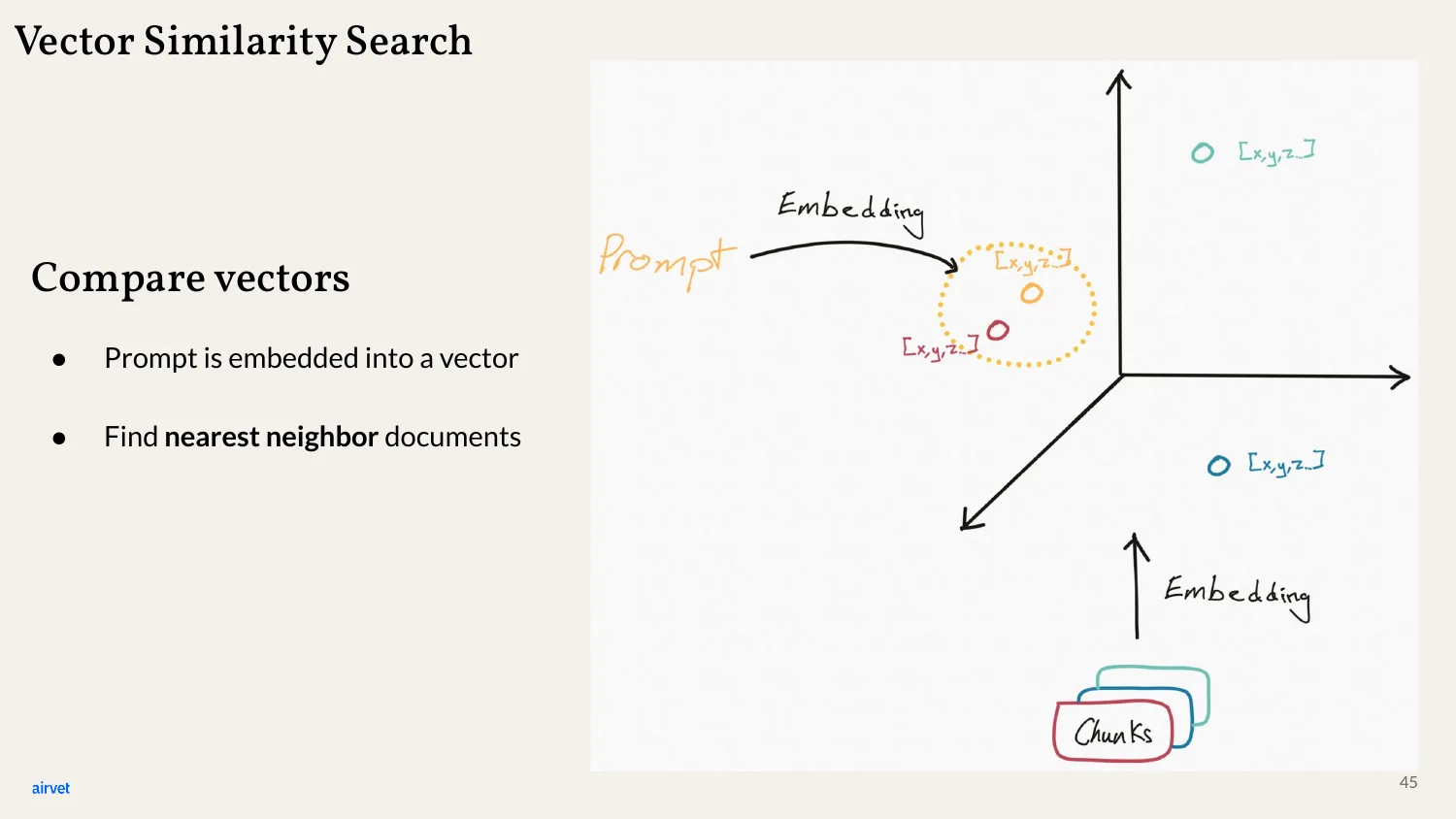
Same diagram, more detail. Prompt → vector. Search the vector store for nearest neighbors. The result is the most semantically relevant chunks for that prompt.
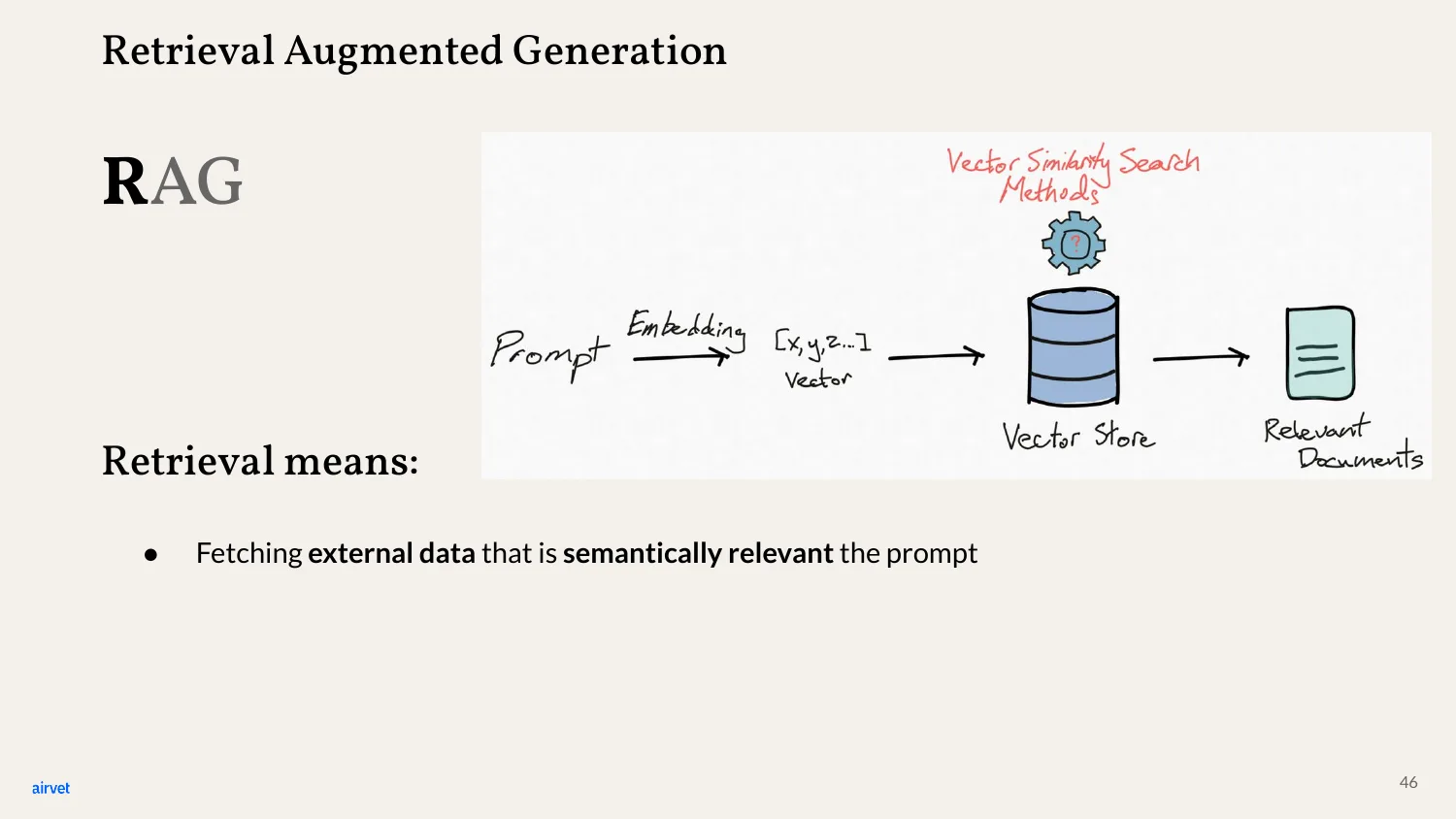
Retrieval means fetching external data that's semantically relevant to the prompt. Not keyword search - semantic. The model can find the right documents even when the query and the documents use different words.
Augmented means passing that fetched data to the model as context - adding information the model wasn't trained on.
Generation means prompting the model to generate an answer grounded in the retrieved data. The response should be based on what retrieval brought back, not just on training.

RAG, in three steps:
- Indexing - break documents into chunks, embed, store.
- Retrieval - find the chunks most relevant to the user's prompt.
- Generation - prompt the model with the retrieved context plus the user's question.
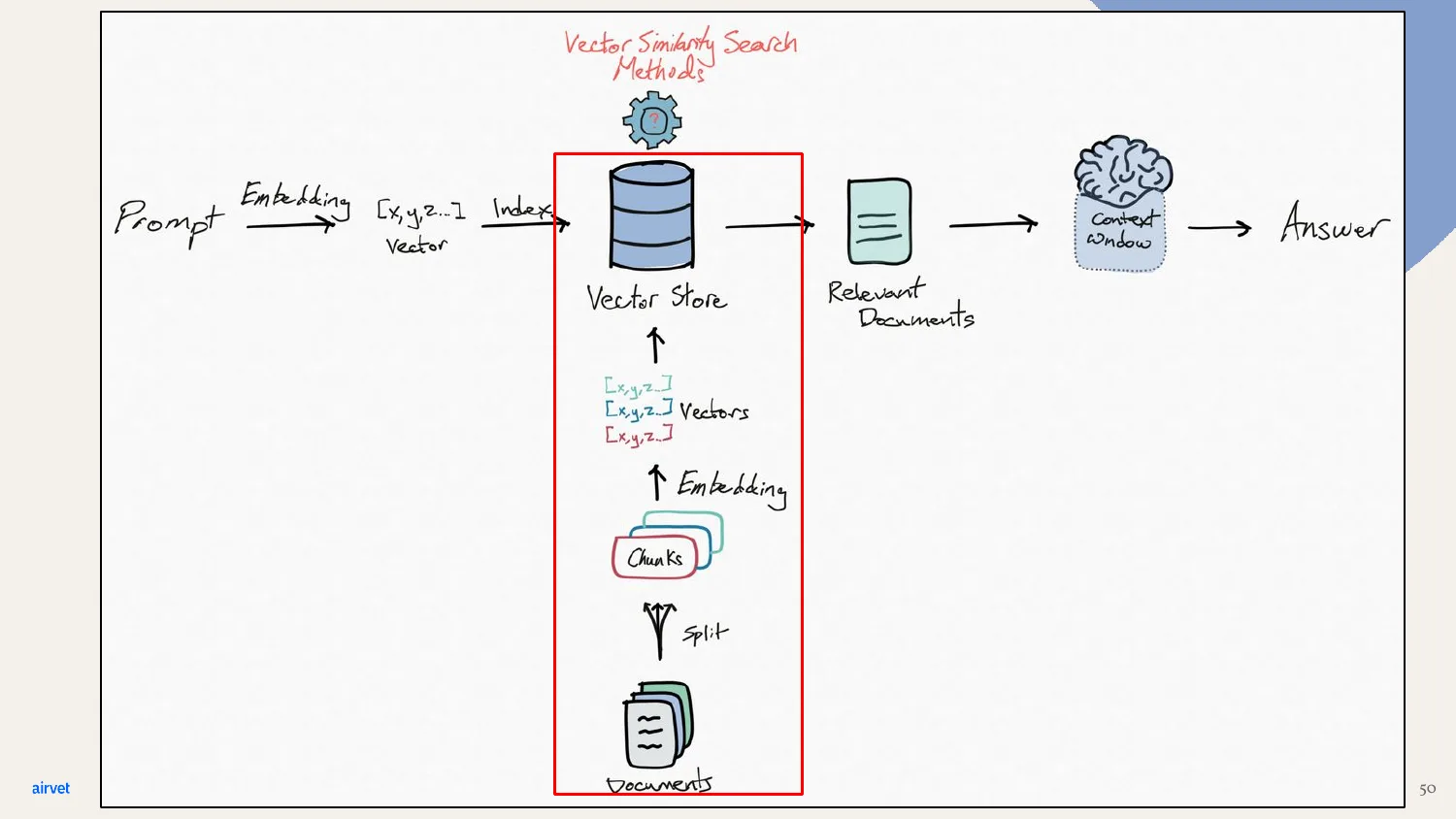
This is what the full RAG pipeline looks like end-to-end. Prompt → embedding → vector search → relevant documents → model → answer. The red box highlights where in the pipeline we are.
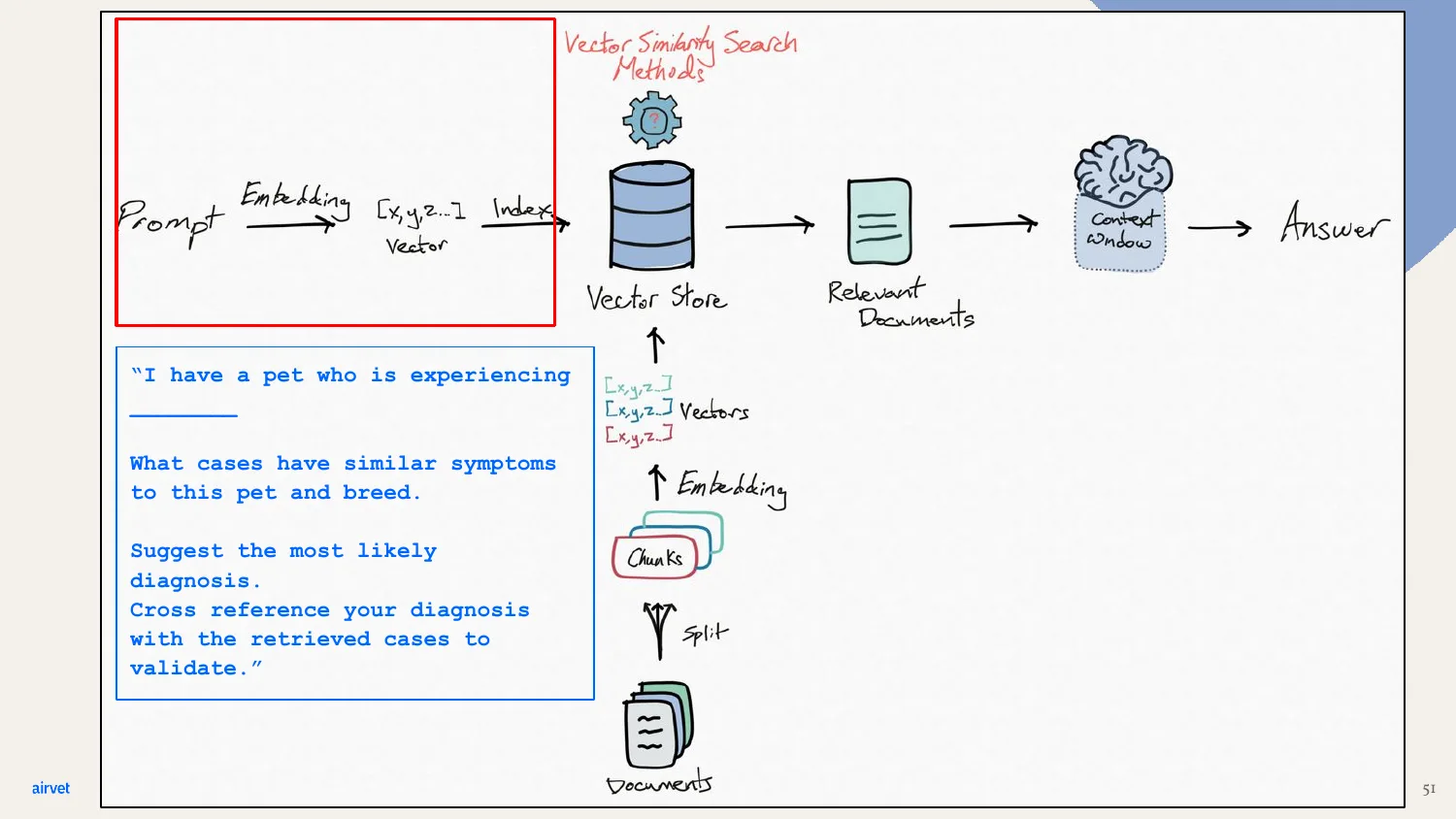
And here's the prompt in our domain. "I have a pet experiencing X. What cases have similar symptoms? Suggest the most likely diagnosis. Cross-reference with the retrieved cases to validate." That's a RAG prompt - the model is told to ground its answer in the retrieved cases.
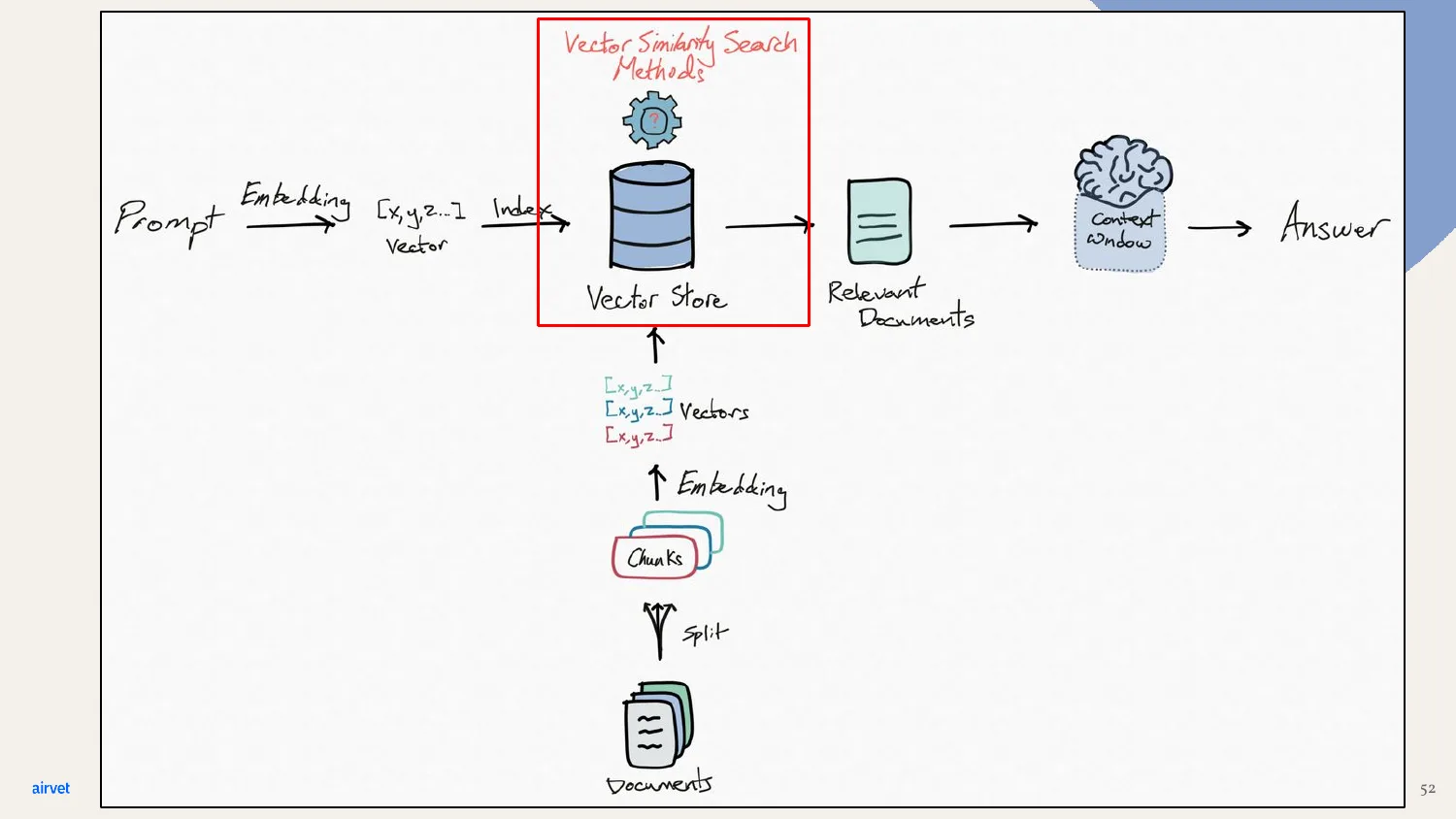
The vector search lives in the middle of the pipeline. It's how we go from the user's natural-language prompt to the specific cases the model needs to reason over.
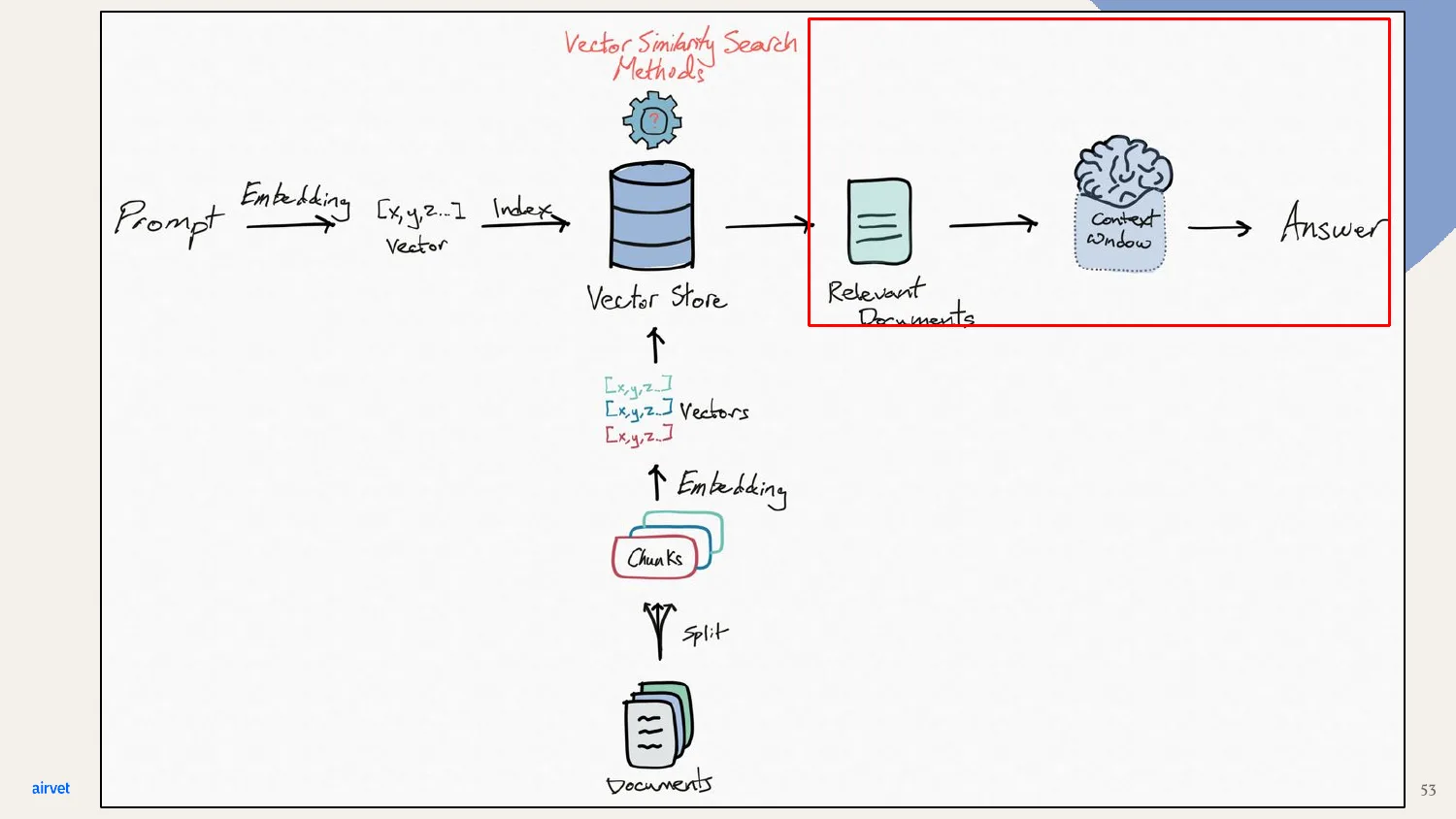
After retrieval, the relevant documents flow into the model alongside the prompt. The model's answer is conditioned on both.

And the closer. Is Airvet + RAG an AI product? Yes. Sort of. The boundaries are fuzzy and that's fine - what matters is whether the thing we ship is useful.
The point of going this deep on the mechanism: when GPT does something surprising, you should be able to trace it back to next-token-prediction-from-vectors-in-a-trained-network and ask which of those steps is producing the surprise. Same for RAG - when retrieval misses, it's usually the embedding step, not the model itself. Naming the parts is most of the debugging.